


Abstract
With the easy adaptability and availability of the opensource AI frameworks like Keras, organizations from all the fields are taking advantage of this emerging technology and trying to pose innovations in individual domains.
Language is a source of expression used by humans to represent their emotions and moods. Specifically, written text is a sign of personal experience.
However, it is not a straightforward task to determine the sentiment of the person using words to express his feelings, because words and language can be deceiving. Emotions like taunt and sarcasm literally mean the opposite of what is expressed in words. For eg, when a teacher says “Very good! Keep it up” when a student gives a wrong answer, just to taunt him.
Or when a customer review’s the best pizza he ever had by writing statutory warning: “Caution! Do not try this Pizza! It is so delectable, that now I can not eat any other Pizza but only this.”
Here, we show how Keras -a high-level neural network API- can be used for Natural Language Processing.
- It can be used by Production Houses to create a movie rating system which analyzes text (movie reviews by the audience) to rate that particular movie without the presence of a movie-critic.
- Also, Record Label companies can make use of this machine learning model of text classification to interpret their listeners choice by their reviews on songs and artists
Keras has the simplest perception and can be easily used by humans, unlike other libraries that are easy to use by machines.
Preconditions
- A text-classification model- using Keras API (tf.keras)- should be built on TensorFlow, Theano, or any other machine learning library, trained on a big dataset of movie reviews (eg. IMDB movie reviews)
- The model should be trained efficiently but should not be overfitted or underfitted with training datasets. Meaning, the movie rating system may not result accurately when the training datasets of movie reviews fed in it are too less or too high.
- The training sets should be balanced, i.e the number of positive movie reviews should be equal to the number of negative movie reviews- for accurate and unbiased text classification.
- The data should be modeled using Bag of Words or Lexicons, which is a dictionary of a pre-classified set of words that is used to test the analyzing statement.
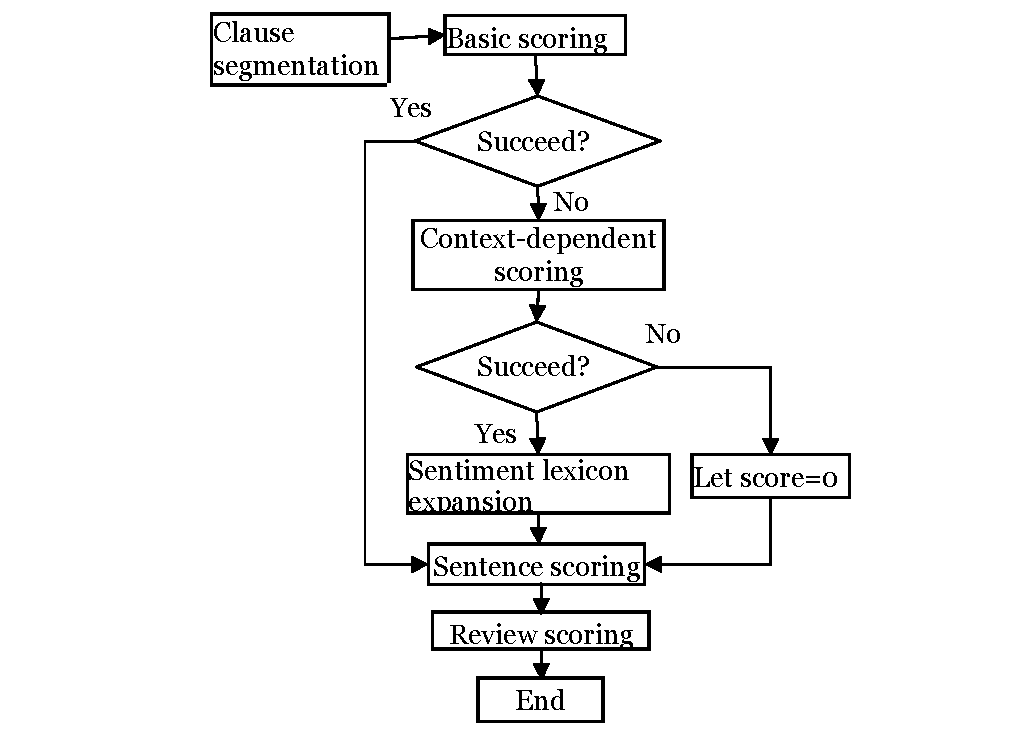
Description
- As soon as a movie is released, the viewers’ reviews can be collected
- Eventually, as more number of movie reviews are collected, they can be passed to our Keras developed ML program
- Step-by-Step Program Execution:
- Tokenization- here the review statement is segregated into individual words
- Cleaning of data- all the special characters (, . / ! @ ? * # ‘ “ etc) that do not add any value to the analytics are removed from the text
- Removal of Stop words- supporting words like pronouns, articles, prepositions, interjections, conjunctions, etc are removed. For eg. the, was, she, under, etc.
- Classification using supervised Algorithm- assigning a sentiment score +1 to a positive word, -1 to a negative word and 0 to a neutral word. Eg. +1 to great, amazing, -1 to boring, bad, and 0 to movie, scene, etc.
- Calculation- finally the rating of the movie is calculated by summing the sentiment score of all the leftover words in the sentence. Whether it sums up to be a positive sentiment overall or negative decides whether the reviewer has liked the movie or not.
- Same way, analyzing all the reviews by different users, the program verdicts the Movie Rating based on the majority
- Thus, the task of critically rating a movie can be automated
The Power Lies In Your Hands.
If you like this blog, then please do share it.
Share This Article On
Post-Conditions
- After the Keras text-classification program has been executed on a movie-review, the producer needs to manage or handle that tested text (movie-review).
- If that similar kind of review is already present in the program’s training data-set, then it should be dumped.
But, if the tested review text is new, it must be fed back into the program, so that the program can learn(train) from it.
